An example output of my home grown graphical analysis tools.
|
|
|
An example output of my home grown graphical analysis tools.
0 Comments
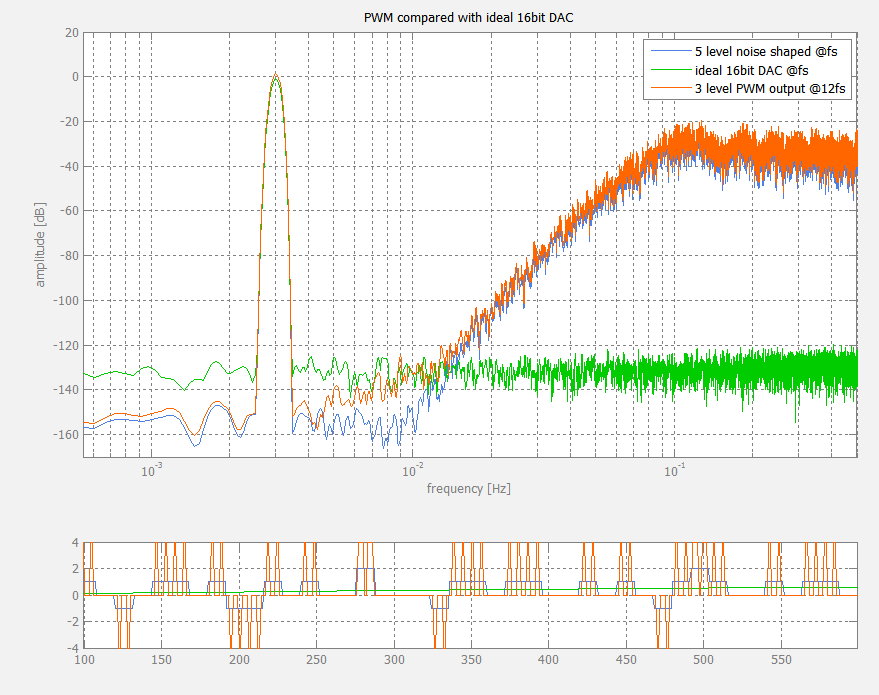 The THD if a digital PWM modulator is quite high, and a great number of complex technologies has been proposed to improve it. With relatively simple trickery it is possible to achieve fairly excellent performance however, as this simulated example of a DAC shows. Two PWM modulators are combined here, and the distortion of each one is almost completely canceled by the other. They must be combined with very high precision for this to work properly, but that is doable: one idea that should work is differentially sampling them with a floating capacitor. As seen on the plot, approximately two decades below fs the noise and distortion levels are beyond what a perfect 16bit DAC (CD quality) could achieve. This would correspond to an fs (noise shaper calculation speed) of 4.41Msps. The PWM modulators require no calculation other than counting and would in this example be clocked at 12 times fs or ~53MHz. This is only an example. The numbers for an optimized practical implementation would probably become different.
All depends on what the objective is.
For telephony, a signal to distortion ratio of 35dB is seen as sufficient for signal levels of -10dB to –30dB below clipping [2]. Sounds horrible, but its enough to render intelligible speech. NICAM (Near Instantaneous Companding Audio Multiplex) is a digital sound transmission system that uses only 10 bits for representing the signal waveform. But these 10 bit are combined with a gain scaling factor of 4 bit that is updated at 1ms intervals. This increases the total dynamic range via simple companding and expanding (actually the same idea as is used by tape noise reduction systems). So NICAM can offer the total dynamic range of a 14 bit system (86dB), but depending on the signal amplitude it has the quantization error that is no better than that of a 9 to 10 bit system and therefore the maximum signal to distortion ratio varies between 56dB and 62dB. This can hardly be called high fidelity, but appears to be sufficient for the needs of stereo TV sound. What if we want audio heaven? What is needed for absolute perfect high fidelity reproduction? Well, a reasonable requirement would be that all distortions are small enough to fall below the human hearing threshold. There can be no doubt that this will make any kind of distortion inaudible. But that is a quite tough requirement. The human ear is extremely sensitive: at the hearing threshold, the magnitude of ear drum vibration is less then the diameter of a hydrogen atom (!). And it has an enormous dynamic range: the pain threshold is 140dB [1] above the hearing threshold, which is a power ratio of ten million times ten million. No music reproduction chain can achieve that dynamic range. However, at sound levels of 120dB above threshold or higher, even very short exposure can cause permanent hearing damage [3], so it is a bit ludicrous to aim for such high playback levels. A "safe" dynamic range requirement might therefore be set at for example 120dB. This is still a power ratio of a million times a million (*). No amplifier on the market can guaranty that level of performance under all conditions all the time for any input signal and any load. Except perhaps the amplifiers that I designed and demonstrated in the '90s (which were never on the market). These could probably (**) do just that, and not only in special lab setups but robustly guarantied by design, whatever happens. These amplifiers achieved up to 120dB loopgain at 10kHz, or a gain-bandwidth product of 10GHz (!). And for achieving this speed they needed only very humble power transistors with an ft of 3MHz. Assuming for the sake of argument that the open loop distortion is 1%, then the closed loop distortion of such an amplifier would be -160dB. As listening test showed, the sound quality of these amplifiers reached absolute perfection, far beyond what any existing high end amplifier technology can ever deliver. Refs [1] Hearing and Deafness, Third edition, Davis & Silverman, figure 2-6. [2] Speech Processing, Chris Rowing, figure 3.2. [3] Audio Engineer’s Reference Book, M Tabot-Smith. Notes (*) A practical example. Assume a 100W amplifier is driving a loudspeaker with 90dB/W sensitivity, a fairly typical situation. At 100W amplifier output power, this combination is capable of producing a sound pressure of 110dB. To produce a sound at hearing threshold level at 3kHz, the amplifier output is only 3nW. (*) This was never proven by measurements due to lack of sensitive enough measurement equipment. But it was shown by simulations. 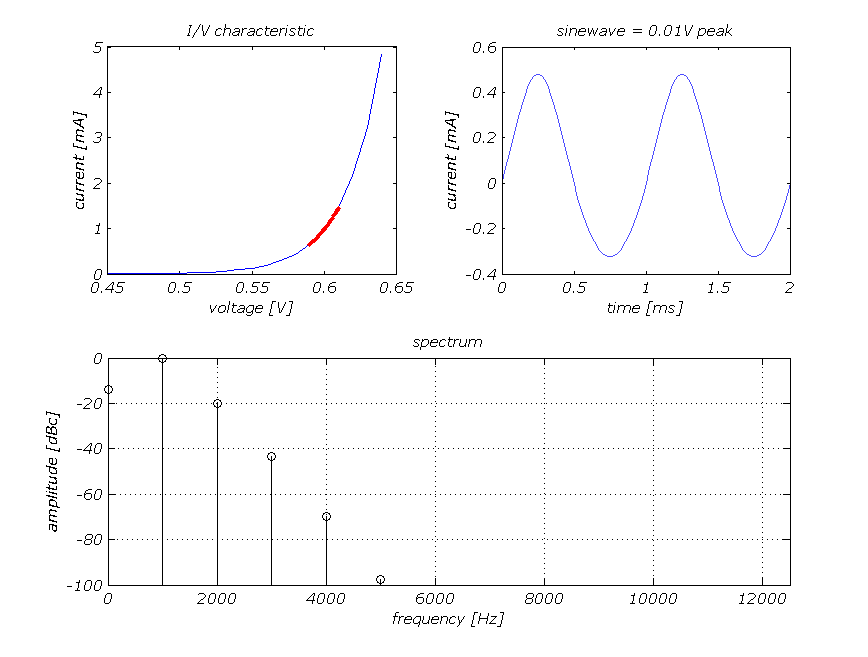
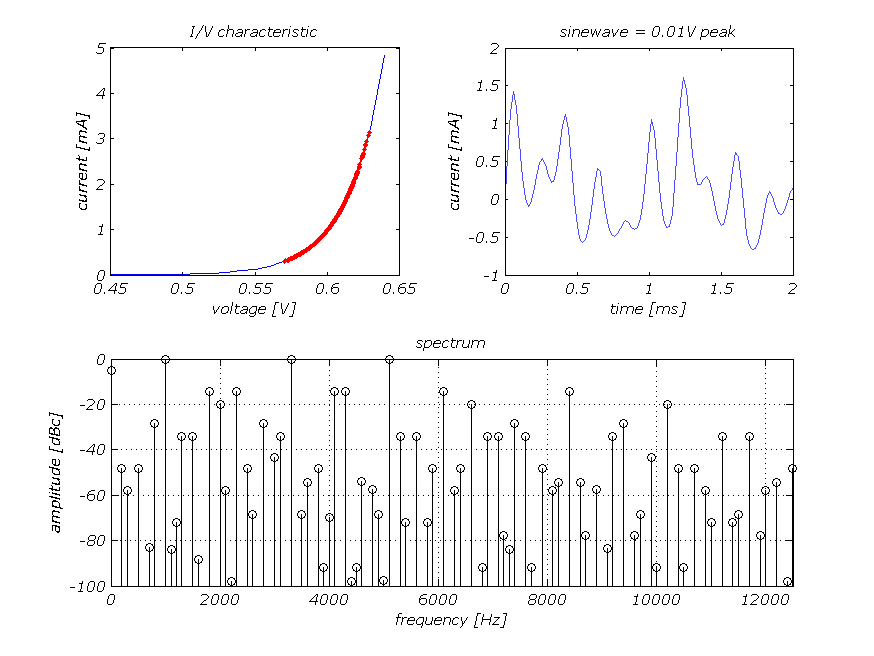
That is easy: because distortion pollutes the audio spectrum. Above we see the distortion components produced by a simple distortion mechanism on a single -40dBV sinewave at 1kHz. A zero feedback transistor stage serves as an example of a smooth transfer curve here. Note the original frequency at 0dB in the spectrum. The argument that a smooth distortion mechanism produces distortion components (harmonics) that will be masked by the ear has some ground, but only for single tones. Music does not consist of a single tones however. The second figure shows what happens at the other extreme: here three -40 dBV sinewaves are present simultaneously at 1 kHz, 3.3 kHz and 5.1 kHz and pass through the same smooth distortion mechanism. No amount of masking will be able to hide the terrible mess of distortion products that now emerges.
. 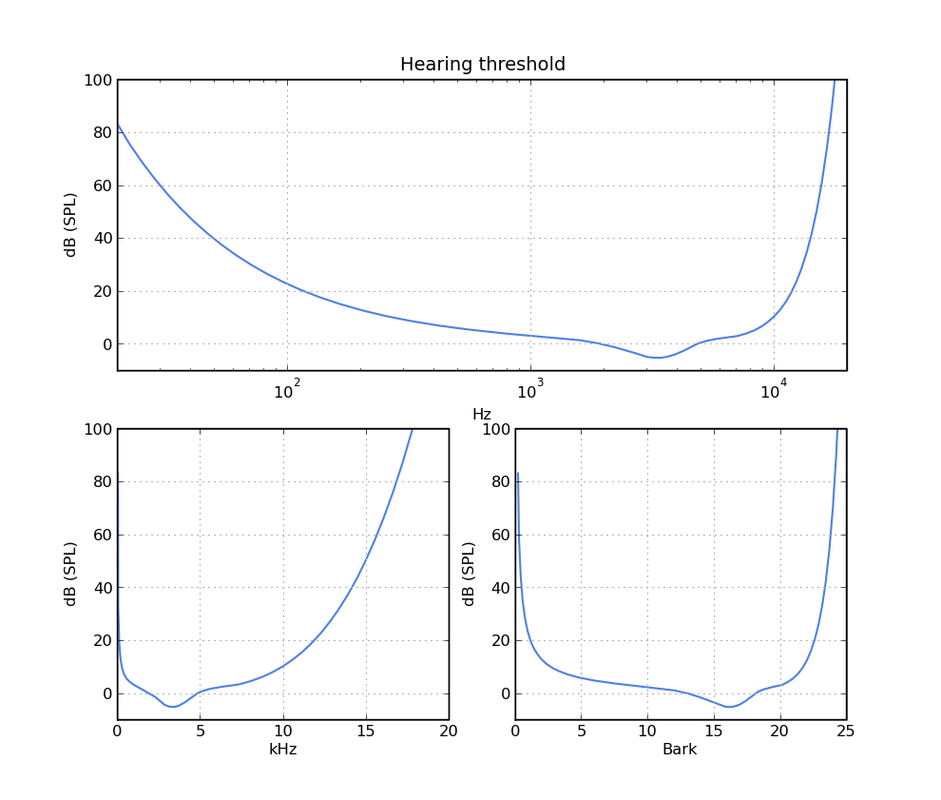 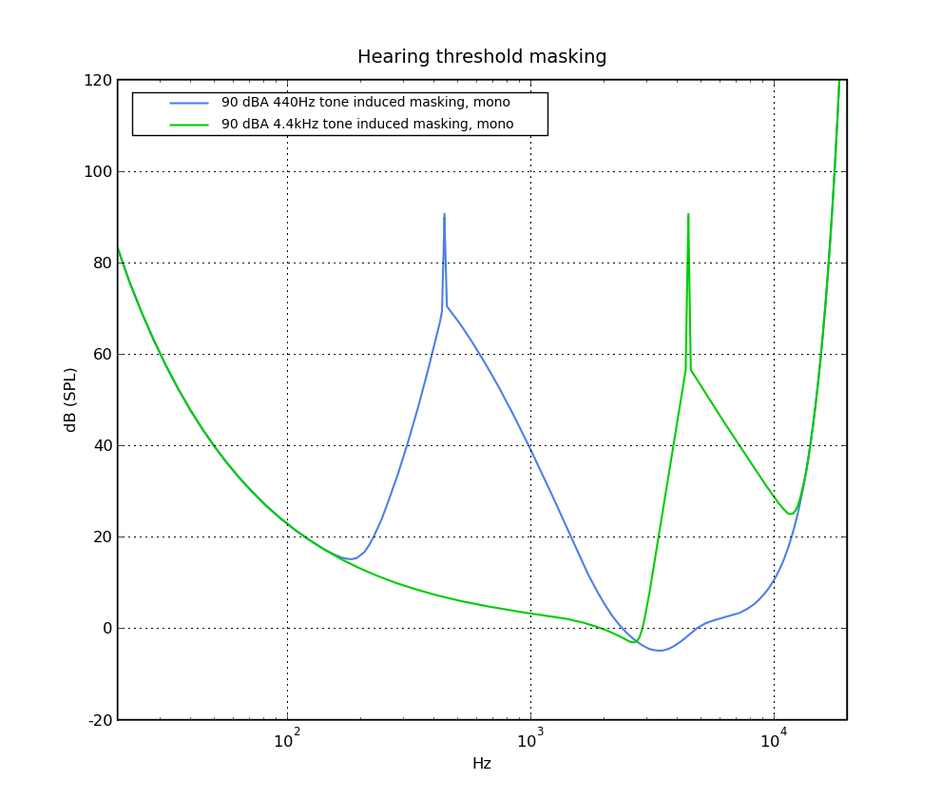 This is the hearing threshold in silence (for a typical human at age 20) on logarithmic, linear and Bark (=perceptual) frequency scales. Below these levels nothing is audible. This is the hearing threshold in the presence of two different tones. Part of the threshold moves upwards, possibly hiding signals that would otherwise be audible. This is called masking. Note however that even in the presence of a loud (90dBA) sound, a considerable part of the threshold is still at the silent level. This explains why very small distortion levels can still be audible. (model: Psychoachoustics, Zwicker 1990) 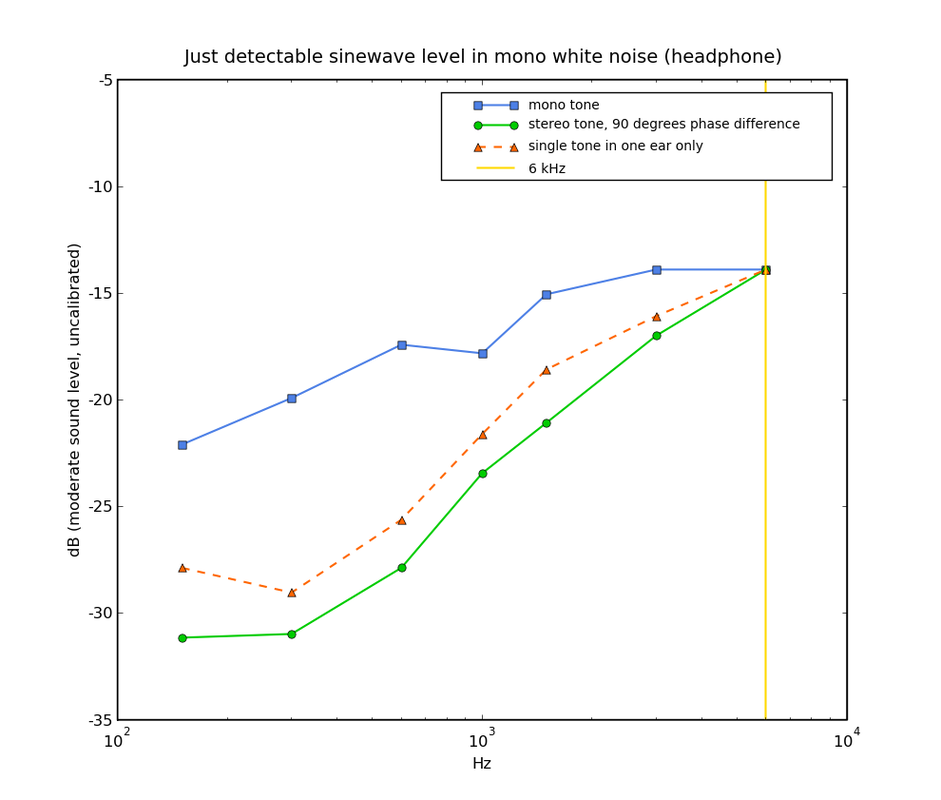 On stereo signals, the ear-brain system can achieve a significant processing gain. In stereo hearing, just by using two ears, directional information translates into amplitude and phase differences between the two ears. If there are phase differences, then a processing gain of up to 15 dB has been observed. That means you can suddenly hear a tone that would be 15 dB below the noise in mono. A simple experiment I did with a headphone (above) already showed 11 dB processing gain at low frequencies. This explains why small distortion levels are more audible on live stereo recordings that contain directional acoustic information. 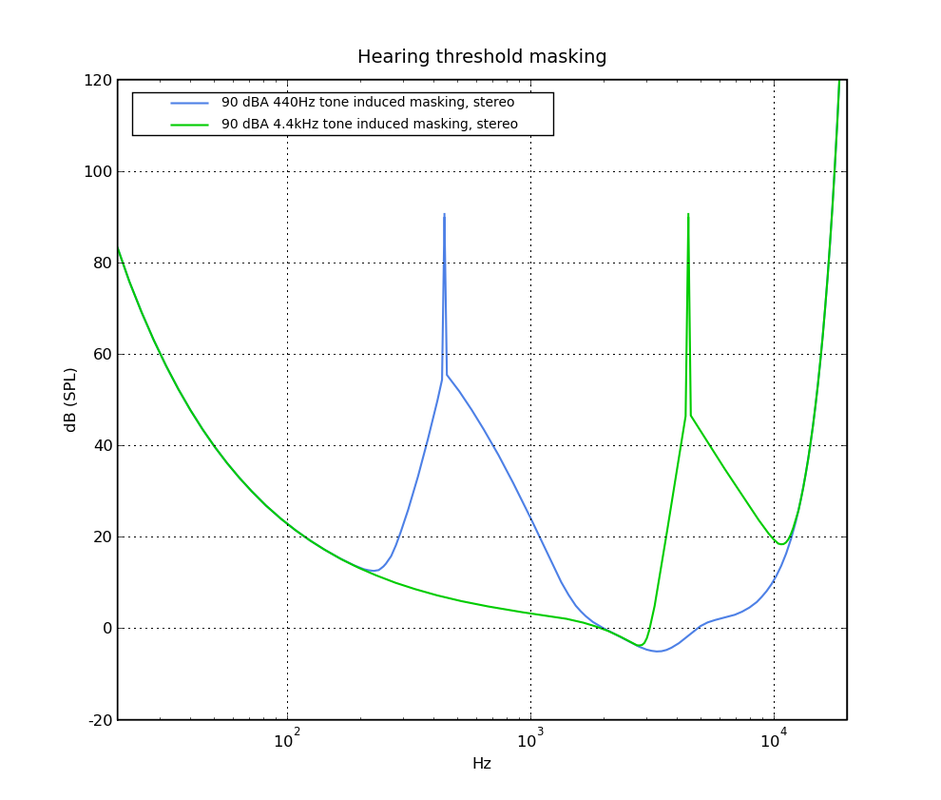 This figure is speculative. I'm not aware of a study that showed if stereo hearing processing gain can be applied to hearing threshold masking. Its an intriguing thought anyway.
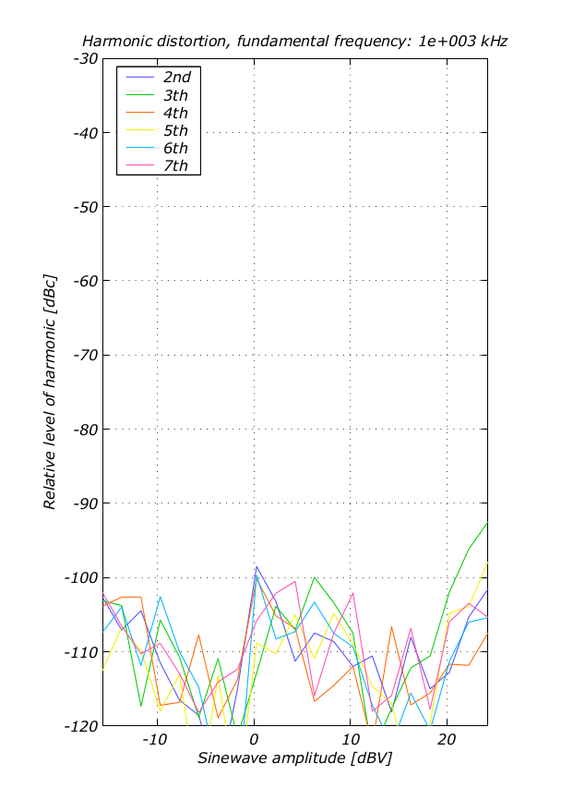 These low distortion levels (at full load) would look pretty good on any hifi audio amplifier. But this particular amplifier had to handle more than a 1000 times faster signals. I developed this amplifier in 2004 as part of a large industrial T&M instrument. The full power signal bandwidth was 30MHz (not 20kHz) and if I remember correctly the signal swing was something like 40Vpp in 20 ohm. As any experienced designer will attest, the technology to achieve this level of performance at these frequencies is not supposed to be available, not in the 21th century anyway.
|
AuthorI'm and electronic circuit developer (30 years experience). ArchivesCategories |
 RSS Feed
RSS Feed
